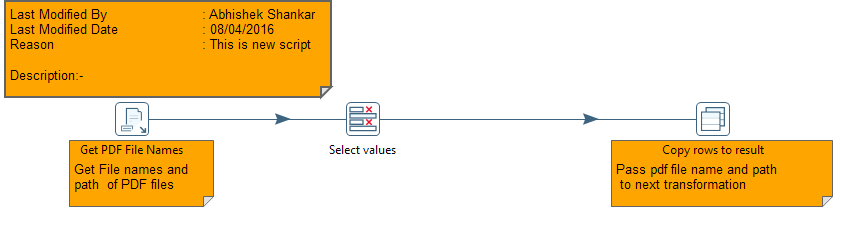
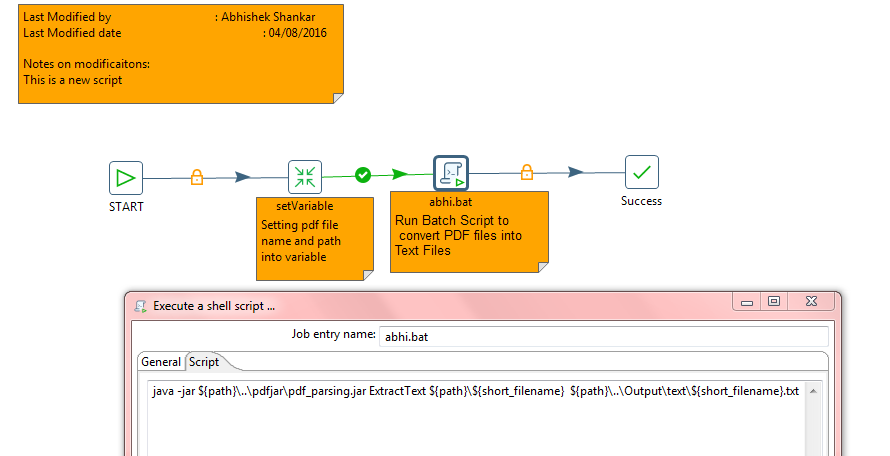
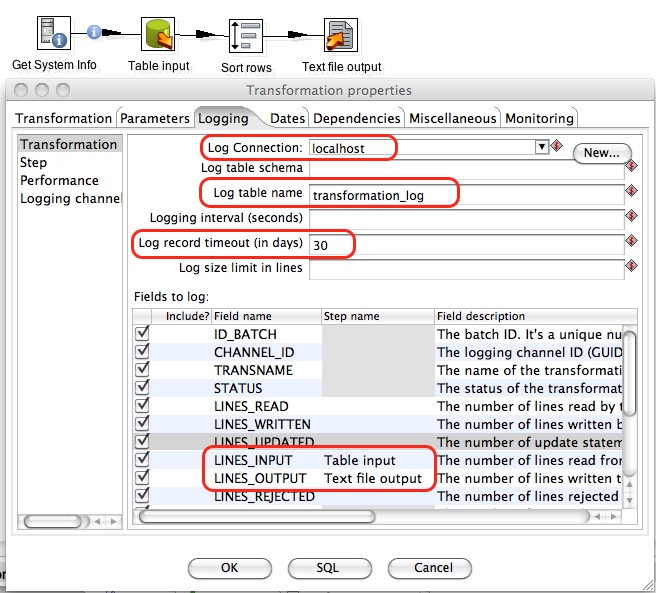
Set Up Kafka and use from pentaho
In this tutorial, I will show how to set up and run Apache Kafka on Windows/linux and how to load/read data from pentaho.
Kafka comes with two sets of scripts to run Kafka. In the
bin folder, the sh files are used to set up Kafka in a Linux environment. In the bin\windows folder, there are also some bat files corresponds to those sh files which are supposed to work in a Windows environment. Some say you can use Cygwin to execute the sh scripts in order to run Kafka. However, they are many additional steps involved, and in the end you may not get the desired outcome. With the correct bat files, there is no need to use Cygwin, and only Server JRE is required to run Kafka on Windows.Step 0: Preparation
Install Java 8 SE Server JRE/JDK
You need Java SE Server JRE in order to run Kafka. If you have JDK installed, you already have Server JRE installed, just check if the folder {JRE_PATH}\bin\server exists. If it is not, follow the following steps to install Java SE Server JRE:
- Unpack it to a folder, for example C:\Java.
- Update the system environment variable PATH to include C:\Java\jre\bin, follow this guide provided by Java.
Download Kafka
- Download the binaries from http://kafka.apache.org/downloads.html
- Unpack it to a folder, for example C:\kafka
Step 1: Update files and configurations
Update Kafka configuration files
The config files need to be updated corresponding to Windows path naming convention.
Change this path if you using Windows
*** Important :- create this path inside Kafka root directory,other wise Kafka server may not start
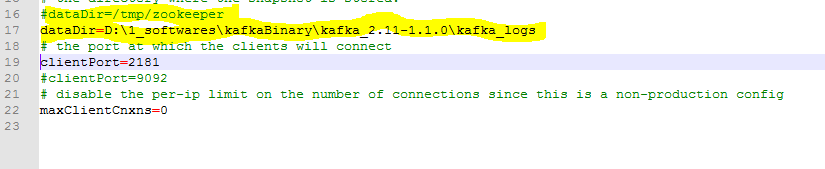
- Open
config\server.properties, change
|
|
to
|
|
2.. Open
config\zookeeper.properties, change
|
|
to
|
|
Step 2: Start the Server
In Windows Command Prompt, switch the current working directory to C:\kafka:
|
|
- Start Zookeeper
- you can create bat file to start Zooker (optional) kafka-server-start.bat and put below conteent kafka-server-start.bat {base folder}\kafkaBinary\kafka_2.11-1.1.0\config\server.properties
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with Kafka to get a quick-and-dirty single-node ZooKeeper instance.
- you can create bat file to start Kafka (optional) kafka-server-start.bat and put below conteent zookeeper-server-start.bat {base folder}\kafka_2.11-1.1.0\config\zookeeper.properties

|
|
Step 3: Create a topic
- Create a topic
Let’s create a topic named “test” with a single partition and only one replica:
|
|
2.. List topics
We can now see that topic if we run the list topic command:
|
|
Step 4: Send some messages
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default each line will be sent as a separate message.
- Start console producer
|
|
2.. Write some messages
|
|
Step 5: Start a consumer
|
|
If you have each of the above commands running in a different terminal then you should now be able to type messages into the producer terminal and see them appear in the consumer terminal.
Yay cheers!
Common Errors and Solutions
classpath is empty. please build the project first e.g. by running 'gradlew jarall'
- Note: Do not download a source files from appache kafka, download a binary file
- Note: Do not download a source files from appache kafka, download a binary file
Kafka java.io.EOFException - NetworkReceive.readFromReadableChannel
Zookeeper may not configured propery (may be configured with different port number)
References
https://kafka.apache.org/
Kafka tool installation:
This is GUI interface of kafka where you can view messages,check count of messages and create and delete Kafka topic
Down load kafka tool from
http://www.kafkatool.com/
Now install executable file in your system
This is very useful tool to view data in kafka


Load data to Kafka Topic using pentaho 8.0:
step 0:-if you are not using pentaho 8 you may require to download kafka producer and consumer from pentaho wiki
https://wiki.pentaho.com/display/EAI/Apache+Kafka+Producer
https://wiki.pentaho.com/display/EAI/Apache+Kafka+Consumer
1.start spoon.bat
2.open spoon canvas
3.Read data from file/database or data grid
4.convert data to valid Json object
5.Load data to kafka topic (may be conversion to valid json object is required)
Download below example from here
https://drive.google.com/file/d/1Ik0RGTSTKphPrGN4M7rwDLhFDpsDbAsd/view?usp=sharing


while using pentaho consumer you can use same configration as shown in above example
Important:-you need to change GROUP ID every time if you want to read data from start.
Some useful Json quary Tips.
Exapmle
---------------
{ "store": {
"book": [
{ "category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{ "category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{ "category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{ "category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
}
}
Json Query Result
| XPath | JSONPath | Result |
/store/book/author | $.store.book[*].author | the authors of all books in the store |
//author | $..author | all authors |
/store/* | $.store.* | all things in store, which are some books and a red bicycle. |
/store//price | $.store..price | the price of everything in the store. |
//book[3] | $..book[2] | the third book |
//book[last()] | $..book[(@.length-1)]$..book[-1:] | the last book in order. |
//book[position()<3] | $..book[0,1]$..book[:2] | the first two books |
//book[isbn] | $..book[?(@.isbn)] | filter all books with isbn number |
//book[price<10] | $..book[?(@.price<10)] | filter all books cheapier than 10 |
//* | $..* | all Elements in XML document. All members of JSON structure. |
References
http://www.jsonquerytool.com/
http://goessner.net/articles/JsonPath/