Both Google Cloud Platform (GCP) and Amazon Web Services (AWS) offer robust services for creating data lakes. The choice between the two depends on various factors, including your specific requirements, existing infrastructure, expertise, and budget. Here are some considerations for each cloud provider:
Google Cloud Platform (GCP) for Data Lakes:
- BigQuery: GCP's BigQuery is a fully managed, serverless data warehouse and analytics platform that can be used as a foundation for a data lake. It offers scalable storage and querying capabilities, along with integration with other GCP services.
- Cloud Storage: GCP's Cloud Storage provides a highly scalable and durable object storage solution. It can be used as a landing zone for ingesting and storing raw data before transforming it into a structured format for analysis.
- Dataflow: GCP's Dataflow is a managed data processing service that enables real-time and batch data processing pipelines. It can be used for data transformation, cleansing, and enrichment tasks within a data lake architecture.
- Dataproc: GCP's Dataproc is a managed Apache Hadoop and Apache Spark service. It provides a scalable environment for running big data processing and analytics workloads on GCP.
Amazon Web Services (AWS) for Data Lakes:
- Amazon S3: AWS's Simple Storage Service (S3) is a highly scalable object storage service that can be used as the foundation for a data lake. It provides durability, availability, and security for storing large volumes of data.
- Amazon Glue: AWS's Glue is a fully managed extract, transform, and load (ETL) service. It can automate the process of cataloging, cleaning, and transforming data to make it ready for analysis within a data lake.
- Amazon Athena: AWS's Athena is an interactive query service that allows you to analyze data directly in Amazon S3 using SQL queries. It provides an on-demand, serverless approach to querying data within a data lake without the need for infrastructure provisioning.
- AWS Lake Formation: AWS Lake Formation is a service that simplifies the process of setting up and managing a data lake. It provides features for data ingestion, metadata management, and access control.
Both GCP and AWS have strong offerings for building data lakes, and the choice depends on your specific needs and preferences. It is recommended to evaluate the features, pricing, scalability, security, and ecosystem of each provider to determine which one aligns best with your requirements and organizational goals.
Here's a comparison of storage types available in Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure:
1. Object Storage:
- GCP: Cloud Storage
- AWS: Amazon S3 (Simple Storage Service)
- Azure: Azure Blob Storage
2. Block Storage:
- GCP: Persistent Disk
- AWS: Amazon Elastic Block Store (EBS)
- Azure: Azure Managed Disks
3. File Storage:
- GCP: Cloud Filestore
- AWS: Amazon Elastic File System (EFS)
- Azure: Azure Files
4. In-Memory Data Store:
- GCP: Cloud Memorystore (supports Redis and Memcached)
- AWS: Amazon ElastiCache (supports Redis and Memcached)
- Azure: Azure Cache for Redis
5. NoSQL Database:
- GCP: Cloud Firestore, Cloud Bigtable
- AWS: Amazon DynamoDB
- Azure: Azure Cosmos DB
6. Relational Database:
- GCP: Cloud Spanner
- AWS: Amazon RDS (Relational Database Service)
- Azure: Azure SQL Database
7. Data Warehousing:
- GCP: BigQuery
- AWS: Amazon Redshift
- Azure: Azure Synapse Analytics (formerly SQL Data Warehouse)
8. Archive Storage:
- GCP: Cloud Storage Coldline, Archive
- AWS: Amazon S3 Glacier
- Azure: Azure Archive Storage
It's important to note that while there are similarities in the storage types provided by GCP, AWS, and Azure, there may be differences in terms of specific features, performance characteristics, pricing models, and regional availability. It's advisable to consult the respective cloud providers' documentation for detailed information on each storage service and evaluate which one best fits your specific requirements.
AWS (Amazon Web Services) offers several services that can be used for data warehousing. Here are some key AWS services commonly used in data warehousing:
1. Amazon Redshift: Redshift is a fully managed data warehousing service that allows you to analyze large volumes of data. It provides a petabyte-scale data warehouse that can handle high-performance analytics workloads. Redshift integrates with various data sources, including Amazon S3, Amazon DynamoDB, and other AWS services. It offers features like columnar storage, parallel query execution, and data compression for efficient data storage and retrieval.
2. Amazon S3 (Simple Storage Service): S3 is an object storage service that can be used as a data lake for storing raw data. It provides scalable storage for structured and unstructured data. You can store data in S3 and then load it into Redshift or other data warehousing systems for analysis. S3 integrates with various AWS services and provides high durability, availability, and security.
Pentaho Can be used as ETL and data loading tool instead of glue/
3. AWS Glue: Glue is a fully managed extract, transform, and load (ETL) service. It allows you to prepare and transform your data for analytics. Glue provides a serverless environment to run ETL jobs, and it automatically generates code to infer schema and transform data. You can use Glue to prepare data for loading into Redshift or other data warehousing solutions.
4. AWS Data Pipeline: Data Pipeline is a web service for orchestrating and automating the movement and transformation of data between different AWS services. It helps you create data-driven workflows and manage dependencies between various steps in your data processing pipeline. Data Pipeline can be used to schedule and automate data movement and transformation tasks for data warehousing.
5. Amazon Athena: Athena is an interactive query service that allows you to analyze data directly from S3 using standard SQL queries. It enables you to perform ad-hoc queries on your data without the need for data loading or pre-defined schemas. Athena is useful for exploratory data analysis and can be integrated with data warehousing solutions for specific use cases.
6. AWS Glue Data Catalog: Glue Data Catalog is a fully managed metadata repository that integrates with various AWS services. It acts as a central catalog for storing and managing metadata about your data assets, including tables, schemas, and partitions. The Glue Data Catalog can be used to discover and explore data stored in S3 or other data sources, making it easier to manage and query data in your data warehouse.
These are just a few examples of how AWS can be used for data warehousing. Depending on your specific requirements and use case, there may be additional AWS services and tools that can be utilized in your data warehousing architecture.
Wednesday 17 August 2022
Pentaho Email Alerting system
Pentaho can used to create an Alerting tool using that any kind of report can be triggered using email.
Some use case example,
Suppose I want todays sales report to get this report just send email to given email id with specific subject like “send me todays sales report” After some time (2-3 min) an email with sales report graphical and tabular as attachment (pdf ,csv, excel ..)will be send to the user.
Data base Artifact report form almost any database can be generated and send on demand to the user .
It can configured to send some alert also
if database/table space is less then 10 %
if any specific query is taking longer than expected to execute.
Top 10 query by performance.
Top 10 table by space used.
It can configured to load data from any excel sheet(from email attachment) to any database in predefined tables.
It configure to execute any batch of shell command directly from email.
Major advantage of this tool is to get reports/Alerts without logging into any system, everything can be triggered using email from specific id.
These reports/Alerts can be scheduled to run on any specific time also,
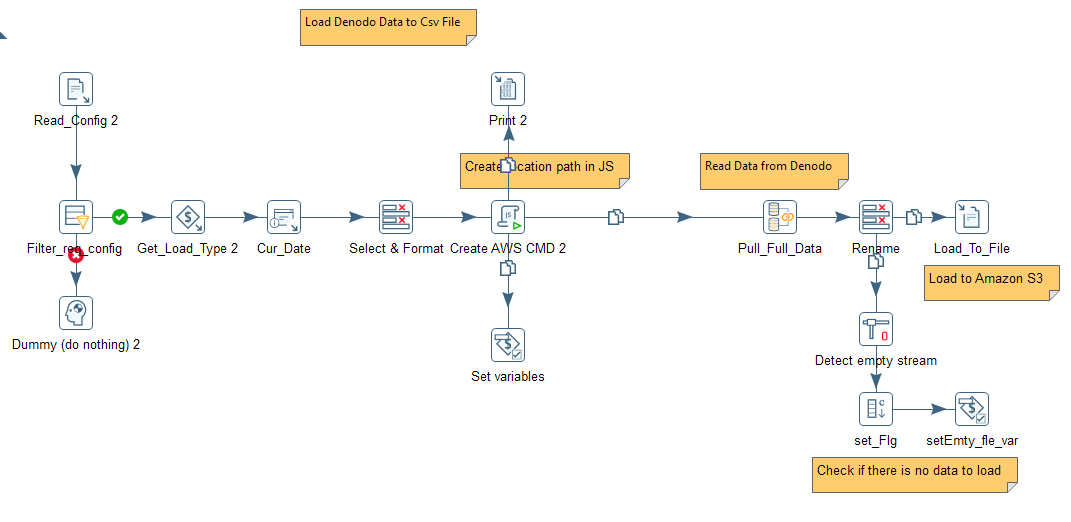
This document explain how to connect neo4j with PDI and load and
retrieve data from PDI, Load Data from CSV to neo4j Neo4j prerequisite
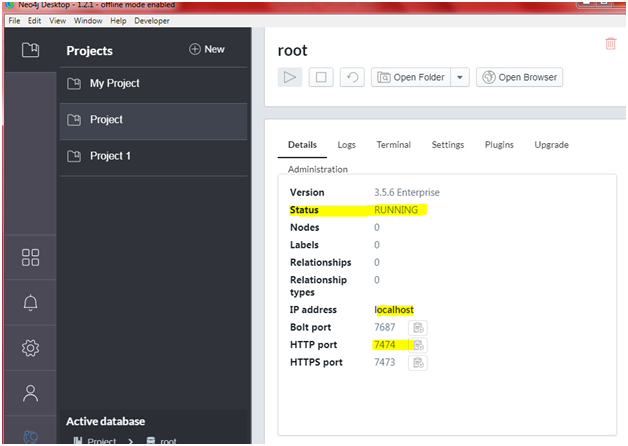
aNeo4j should be up and running
All required credentials including username and password should be
available
c Example below screenshot. Download working copy of above example from here and 2ndFile Load data to neo4j from csv download working copy from here and example csv file from here
How to Connect Neo4j from PDI
1. Get JDBC driver
d)Get the jdbc driver
from below location.This
driver is pre complied and ready to use.this driver hasbeen tested with pentaho
pdi 8.2 and Neo4j desktop 3.5.6.
1.Create main and sub transformation as discussed below
2.call sub transformation from main Transformation
Note:-Sub transformation required for Kafka consumer step
Download working sample from here
https://drive.google.com/open?id=1Z4C2miczU0BnB4n3r1LcpN78v2UjefWQ
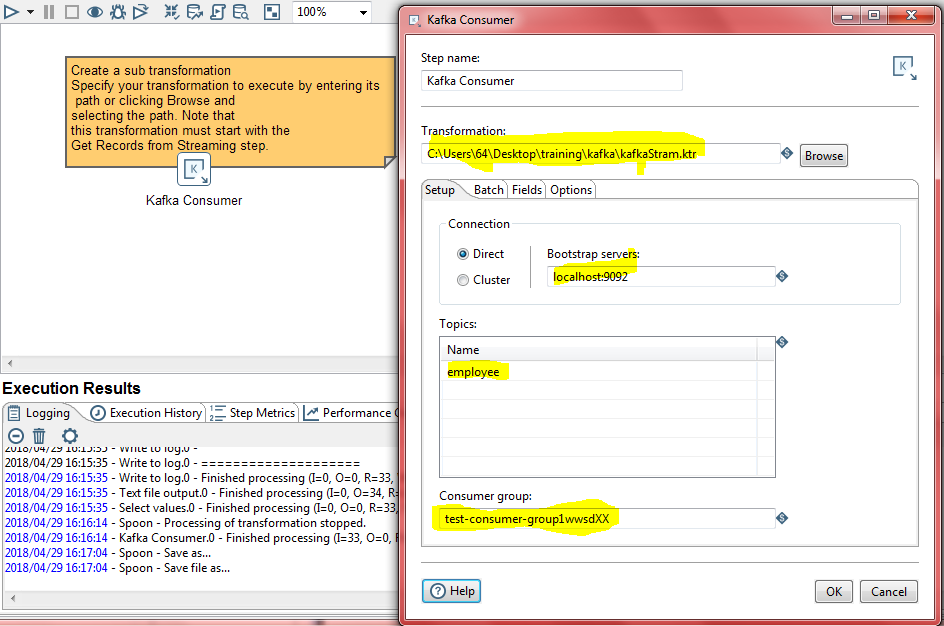
In the kaka transformation,
1.We are using direct bootstrap server on connection.
2. we added the consumer group "test-consumer-group1" change consumer group after every run to retrieve Kafka message from start.
Important:-if you not change consumer group, kafka will not retrieve any message unless any new message arrived to topic.
like test-consumer-group1,test-consumer-group2,test-consumer-group3 .....
3. Changed the auto.offset.reset to "earliest" on options tab.
In the sub transformation.
In "Get records from stream" step, we gave the below fields Fieldname Type key None message None topic None partition None offset None timestamp Timestamp
In this tutorial, I will show how to set up and run Apache Kafka on Windows/linux and how to load/read data from pentaho.
Kafka comes with two sets of scripts to run Kafka. In the bin folder, the sh files are used to set up Kafka in a Linux environment. In the bin\windows folder, there are also some bat files corresponds to those sh files which are supposed to work in a Windows environment. Some say you can use Cygwin to execute the sh scripts in order to run Kafka. However, they are many additional steps involved, and in the end you may not get the desired outcome. With the correct bat files, there is no need to use Cygwin, and only Server JRE is required to run Kafka on Windows.
Step 0: Preparation
Install Java 8 SE Server JRE/JDK
You need Java SE Server JRE in order to run Kafka. If you have JDK installed, you already have Server JRE installed, just check if the folder {JRE_PATH}\bin\server exists. If it is not, follow the following steps to install Java SE Server JRE:
The config files need to be updated corresponding to Windows path naming convention.
Change this path if you using Windows
*** Important :- create this path inside Kafka root directory,other wise Kafka server may not start
Open config\server.properties, change
server.properties
1
log.dirs=/tmp/kafka-logs
to
server.properties
1
log.dirs=c:/kafka/kafka-logs
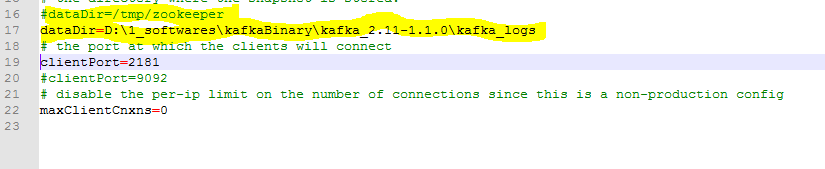
2.. Open config\zookeeper.properties, change
zookeeper.proerties
1
dataDir=/tmp/zookeeper
to
zookeeper.properties
1
dataDir=c:/kafka/zookeeper-data
Step 2: Start the Server
In Windows Command Prompt, switch the current working directory to C:\kafka:
1
cd C:\kafka
Start Zookeeper
you can create bat file to start Zooker (optional) kafka-server-start.bat and put below conteent kafka-server-start.bat {base folder}\kafkaBinary\kafka_2.11-1.1.0\config\server.properties
Kafka uses ZooKeeper so you need to first start a ZooKeeper server if you don’t already have one. You can use the convenience script packaged with Kafka to get a quick-and-dirty single-node ZooKeeper instance.
you can create bat file to start Kafka (optional) kafka-server-start.bat and put below conteent zookeeper-server-start.bat {base folder}\kafka_2.11-1.1.0\config\zookeeper.properties
Kafka comes with a command line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. By default each line will be sent as a separate message.
Start console producer
1
> .\bin\windows\kafka-console-producer.bat --broker-list localhost:9092 --topic test
If you have each of the above commands running in a different terminal then you should now be able to type messages into the producer terminal and see them appear in the consumer terminal.
Yay cheers!
Common Errors and Solutions
classpath is empty. please build the project first e.g. by running 'gradlew jarall'
Note: Do not download a source files from appache kafka, download a binary file